
Un Nobel dimenticato

INTRODUZIONE GENERALE
Quando si prende in esame lo studio nel campo biologico e si vogliono
approfondire i temi che lo costituiscono, il punto di partenza, che permette di
fondare le basi per gli argomenti futuri più complessi e specialistici, è
costituito dall’analisi dettagliata delle cosiddette “macromolecole biologiche”, ossia, come da definizione classica,
quelle “molecole contraddistinte da dimensioni notevoli e da un peso molecolare
molto elevato”. In questo primo articolo, dunque, andremo ad analizzare queste
macromolecole, ponendo però poi al centro del discorso le proteine e la loro
funzione all'interno delle cellule, passando per gli studi del premio Nobel Gunter
Blobel sullo “Zip Code” proteico, il
“codice postale” che indirizza non
solo queste ultime ma anche la nostra prima pubblicazione.
LE MACROMOLECOLE BIOLOGICHE
Per la biologia moderna, le macromolecole biologiche si suddividono in
quattro sottogruppi principali all’interno dei quali possiamo trovare i glucidi
(denominati comunemente carboidrati, da “idrati di carbonio”), le proteine, i
lipidi ( o grassi) e gli acidi nucleici. Cerchiamo ora, osservandole più da
vicino, macroscopicamente parlando, di capirne strutture e funzioni primarie.
I glucidi o glicidi, sono composti chimici
organici, formati da lunghe catene di carbonio, idrogeno e ossigeno. Essi
svolgono innumerevoli compiti all’interno dei sistemi degli esseri viventi:
fungono ad esempio da preziose fonti di
energia e di trasporto della
stessa; hanno un importante compito dal punto di vista strutturale, e giocano, inoltre, un ruolo fondamentale nel sistema immunitario, nella fertilità e nelle fasi dello sviluppo. La loro classificazione scientifica è
particolarmente complessa e varia, ma a seconda della ripetitività degli
elementi chimici che li costituiscono, possono essere suddivisi in monosaccaridi (tra cui spiccano il
glucosio, il fruttosio, il galattosio, il ribosio e il deossiribosio), gli oligosaccaridi (tra cui i più
impostanti vi sono i disaccaridi e i
trisaccaridi), ed infine i polisaccaridi (il cui composto più
annoverato è sicuramente l’amido). Una delle classificazioni ancora ricordate
ed utilizzata è quella che suddivide i glucidi in carboidrati semplici (monosaccaridi e oligosaccaridi) e in carboidrati complessi (polisaccaridi).
I lipidi vengono invece
classificati in base alle caratteristiche che assumono nei confronti della solubilità. La loro struttura, essendo
anch’essi elementi chimici organici, è formata da atomi di carbonio e di
idrogeno, che si uniscono tra loro grazie a dei legami covalenti apolari, che danno così origine al loro classico
comportamento idrofobico. Tuttavia,
ricordiamo anche l’esistenza dei fosfolipidi,
che unendosi danno origine alla membrana plasmatica delle cellule e che
presentano, un comportamento anfipatico:
in parte apolare e in parte polare.
La vasta differenza strutturale permette una grande classificazione, che
li suddivide in lipidi aciclici, ciclici e policiclici. Come già osservato anche nei glucidi, esiste un’altra
importante modalità di classificazione, che si basa sulla complessità dei
grassi stessi: avremo perciò dei lipidi semplici,
complessi e derivati. Esistono ovviamente altre denominazioni provenienti da
accademie differenti, tra le quali quella della Lipid Classification and Nomenclature Committee, celebre per aver
coniato i termini acidi grassi, fosfolipidi (precedentemente nominati)
e glicolipidi.
Il loro ruolo fisiologico primario è quello di riserva energetica, vista l’eccellente capacità di mobilitare grosse quantità di calorie.
Gli acidi nucleici sono
essenziali e fondamentali per tutte le specie viventi, poiché contengono e
trasmettono l’informazione genica.
Essi si suddividono in due classi, il DNA
(denominato acido desossiribonucleico) e l’ RNA (o acido ribonucleico), i quali si differenziano per lo
zucchero che è alla base della loro formazione. Essi sono i prodotti della polimerizzazione per condensazione di monomeri chiamati nucleotidi: quest’ultimi sono caratterizzati dalla struttura che
possiedono, formata tramite l’unione di uno zucchero, una base azotata
e di un gruppo fosfato.
Le basi azotate si
differenziano in puriniche, quando
sono costituite da un doppio anello (si vedano l’adenina e la guanina) e pirimidiniche, costituite da un anello
semplice (di cui fanno parte timina,
citosina e l’uracile dell’ RNA). L’accoppiamento
di queste basi azotate avviene per complementarietà:
ad una base di adenina se ne unisce una di timina o di uracile (A-T / A-U, a seconda del fatto se ci troviamo nel DNA o nell’ RNA); ad
una base di citosina invece se ne unisce una di guanina (C-G).
Le proteine, definite anche protidi invece, sono costituite da
lunghe catene formate da residui
amminoacidici, che prendono il nome tecnico-scientifico di polipeptidi (il numero di polipeptidi
uniti che caratterizza una proteina specifica è dato da un’informazione genica), alle quali sono correlate innumerevoli funzioni che avvengono
all'interno degli esseri viventi e delle loro cellule: ricordiamo ad esempio la
catalisi delle reazioni metaboliche, alcune funzioni
di sintesi, come la replicazione del DNA; presentano ancora delle funzioni
di tipo strutturale, come nei casi
dell’actina e della miosina che permettono la contrazione muscolare, nonché presenti
e attive come risposta immunitaria:
insomma, le proteine partecipano praticamente ad ogni processo che avviene
all’interno degli organismi viventi, siano essi vegetali o animali.
Il corso dell’evoluzione per le proteine è stato lungo e complesso, e ad
oggi si possono identificare più di 500
famiglie proteiche. Risulterebbe molto complesso allora e pressoché
impossibile costituire una classificazione unitaria e precisa per ognuna di
queste catene, e si è dunque deciso di procedere per stilare una tassonomia
proteica universale basandosi sulle caratteristiche
della loro formazione chimica, alla solubilità ed alla configurazione
molecolare. Sulla base di questi
criteri, oggi possiamo distinguere due macro-gruppi separati di proteine: le proteine semplici e le proteine coniugate. Volendo fornire alcuni
esempi pratici, tra gli esponenti principali del primo gruppo proteico,
possiamo ritrovare tutte quelle proteine
fibrose insolubili in acqua tra cui il collagene
(essenziale costituente del tessuto connettivo), l’elastina, la cheratina
(componente più conosciuto che costituisce l’epidermide e le unghie);
nel secondo gruppo dominano invece l’emoglobina
(contenuta negli eritrociti o globuli rossi, volgarmente parlando), le clorofille e le opsine.
Le proteine semplici rientrano nei costituenti delle ossa, dei peli, delle unghie (come già osservato in
precedenza con la cheratina), mentre
sempre fondamentali sono le proteine globulari, alla base dell’economia cellulare, tra cui ricordiamo
nello specifico gli enzimi, gli ormoni, e soprattutto gli anticorpi, i protagonisti delle risposte
immunitarie degli organismi. Si deve
altresì ricordare che molti degli allergeni
e delle tossine presenti in natura,
discendono dalla famiglia delle proteine.
LO “ZIP CODE”: DALLE BASI ALL’ORIGINE ED IL FUNZIONAMENTO OPERANTE
Una delle caratteristiche associata alle proteine consiste nel fatto che
nello svolgere tutta la serie di compiti e funzioni che sono loro deputate e
preposte dal comando centrale (nient’altro che l’informazione genica appunto)
esse debbano necessariamente essere trasportate attraverso le membrane
delle cellule, ossia tra una vicina
od adesa ad un’altra o attraverso i
doppi strati fosfolipidici che separano le parti interne della cellula e degli
organelli dal fluido citoplasmatico che li contiene. Molti studiosi, in
particolare i membri del Dipartimento
di Biologia Sperimentale e di Laboratorio
e dei Laboratori di Biologia Cellulare dell’ Università
di Rockefeller, nello stato di New
York, USA, hanno continuato, seguendo una tradizione già avviata nei primi
lontani anni del 1950, lo studio e le ricerche legate ai segnali d’indirizzo
delle varie proteine che sono dunque mosse secondo principi precisi in una
determinata cellula, attraverso la sua membrana, e non in una modalità casuale
senza schemi fissi o punti di riferimento come si potrebbe pensare: si
presupponeva dunque l’esistenza di
una correlazione intrinseca tra una proteina ed un probabile
segnale che indirizzasse
quest’ultima all’interno di ciascuna
unità biologica. Il punto d’avvio è costituito dagli studi approfonditi
che compì il medico romeno naturalizzato statunitense George Emil Palade, direttore delle ricerche di
biologia cellulare, nonché definito come il più influente biologo cellulare mai
nato, insignito tra l’altro, nel 1974, del Premio
Nobel per la Medicina e Fisiologia.
Da qui allora il professor Günter Blobel, il vero centro del
nostro articolo, cominciò le sue ricerche, trascorrendo giorni, settimane e
mesi per giungere ad una conclusione verificabile con le teorie che fino a poco
tempo prima altro non erano state che mere supposizioni.
Nel 1971, venne formulata la prima versione di quella che venne poi
ribattezzata “ipotesi del segnale”,
la quale costituiva le vere fondamenta della ricerca che avrebbe portato poi
alla scoperta ed ai suoi risultati più che positivi e funzionali e di rilevanza
assoluta nel campo medico. Si scoprì il vero itinerario compiuto dalle proteine
sintetizzate dai ribosomi, che passavano in principio dal reticolo endoplasmatico
fino ad arrivare poi all'apparato di
Golgi ed essere poi liberate passando
oltre la membrana o inviate a compiere le loro funzioni in alcuni dei
determinati organelli.
Nel 1980, dopo anni di ulteriori studi e ricerche avvenute insieme ad
altri collaboratori, Blobel formulò la teoria
generale relativa allo studio sulle
proteine derivante dalla precedente, la quale specificava che ciascuna proteina conteneva con informazioni
intrinseche necessarie per raggiungere la propria
localizzazione nella cellula, il
cosiddetto “segnale topogenico” , in un determinato
organello o ancora nel caso in cui essa avesse dovuto fondersi all'interno
della membrana plasmatica (divenendo appunto una proteina di membrana).
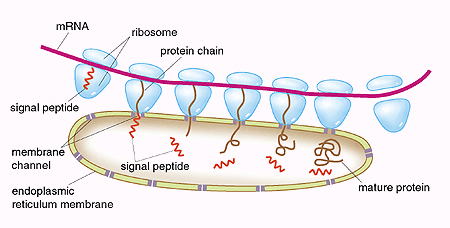
Tutta questa grande scoperta, che giunge al compimento la sera di Natale
del 1974, studiando ed analizzando in provetta la sintesi di proteine del pancreas di un cane (organo in grado di processare una grandissima quantità di
proteine), dopo aver provato con quasi ogni altra sorta di essere animale
vivente, dai topi, ai polli ai piccioni, alle cavie, funge da coronazione per
il lavoro di una vita. Questa grande scoperta, lo portò a vincere innumerevoli
premi tra cui il Premio Lasker, nel 1993 ed il Premio Nobel in Medicina e Fisiologia del 1999.
Il segnale peptidico alla base della scoperta di
Blobel ha permesso un incredibile sviluppo dal punto di vista scientifico e medico, dato che enormi passi avanti sono stati compiuti nei
confronti dello studio di rimedi per curare
malattie gravi come la fibrosi cistica, il morbo di Alzheimer,
nonché l’AIDS ed altre varie forme di cancro.
RINGRAZIAMENTI
Non ebbi mai l’onore di conoscere personalmente questa grande
personalità scientifica che tanto diede al suo tempo e che ancora oggi, grazie
alle sue scoperte, continua a dare alla medicina nella lotta contro i grandi
mali che sempre di più colpiscono l’essere umano, ma dalle buone parole di chi
l’ha conosciuto, di chi ha vissuto con lui come vicino di porta, nemmeno di
casa, dialogato e lavorato per lui, tra cui il mio caro nonno, è un grandissimo
piacere e dovere che mi sono prefissato il portare a termine questa prima
pubblicazione della rubrica “Everyday Biology”, per far sì che scoperte
specifiche come queste non vengano dimenticate mai, e che Premi Nobel, ma prima
ancora PERSONE del peso di Gunter Blobel, cadano nell’oblio e nel ricordo dei
soli cari.
S. F.
V B Liceo delle Scienze Umane
BIBLIOGRAFIA E RIFERIMENTI
- https://www.treccani.it/enciclopedia/gunter-blobel/
- https://aulascienze.scuola.zanichelli.it/blog-scienze/biologia-e-dintorni/in-memoria-di-gunter-blobel
- https://www.nobelprize.org/prizes/medicine/1999/blobel/facts/
- https://www.youtube.com/watch?v=RtngQAaV-pQ&t
- https://www.youtube.com/watch?v=QkbyvtMwPOg&t
- https://www.youtube.com/watch?v=QkbyvtMwPOg&t
Commenti
Posta un commento